Мало кто из разработчиков задумывается о том, как устроено ядро PHP и что происходит «под капотом». Действительно, на практике большинству редко бывают нужны подобные знания, тем не менее обладать ими будет полезно. Статья рассказывает о том, как устроены строки в PHP и о различиях работы с ними в PHP 5 и 7.
Это мой первый перевод подобной статьи, тем более технически не самой простой. Обо всех неточностях пишите в комментариях или лично мне.
Введение
Управление строками всегда было проблемой при разработке программ на C. Если вы думаете о небольшой автономной C программе, просто не беспокойтесь о строках: используйте libc функции, или, если вам нужна поддержка юникода, используйте специальные библиотеки. Существует множество библиотек для самых различных случаев, а если вы ведущий C разработчик, вы легко можете разработать свою собственную, если это необходимо.
В C, строки это простые массивы char. Тем не менее, при проектировании языков сценариев, например PHP, возникает необходимость управления строками в нём. В области управления, мы думаем о классических операциях, таких как конкатенация, поиск, а так же о более продвинутых концепциях, таких как специальные алгоритмы распределения, пул строк, сжатие. Libc реализует простые операции (конкатенация, поиск, усечение), но сложные мы реализуем самостоятельно.
Давайте посмотрим вместе как строки реализуются в ядре PHP 5, и какие основные различия с PHP 7.
Путь PHP 5
В PHP 5 строки не имеют свою собственную C структуру. Да, я знаю, это может показаться чрезвычайно удивительным, но это так. Мы продолжаем играть традиционным способом с C NUL-терминированными массивами символов, которые часто пишутся как char *. Тем не менее, мы поддерживаем то, что называется «двоичной строкой», которые могут содержать NULL символ.
Строки, включающие NULL символ, не могут быть непосредственно переданы в классические libc функции, но должны быть посланы на специальные функции (которые существуют также и в libc), учитывающие длину строки.
Следовательно, PHP 5 запоминает размер строки вместе с самой строкой (char *). Очевидно, что PHP не поддерживает юникод изначально, а строки хранятся как C ASCII символы, и их длина содержит количество символов, как мы всегда считали, один символ = один байт, по давней 50-летней концепции Cи строк, основанной на ASCII. Если один графический символ хранится более, чем в 1 байте, вся концепция, представленная тут, становится ложной. Мы всегда предполагаем, что один графический символ помещается в 1 байт (без поддержки Unicode). Так же нужно помнить, что char * может содержать любой байт, а не только печатные символы.
Один C символ помещается в 1 байт. Это утверждение верно везде, во всём мире, вне зависимости от устройства/платформы. Когда мы говорим о простом ASCII, а не Unicode, один char = один печатный символ.
В конечном счёте мы имеет что-то такое:
typedef union _zvalue_value {
long lval;
double dval;
struct {
char *val; /* C string buffer, NULL terminated */
int len; /* String length : num of ASCII chars */
} str; /* string structure */
HashTable *ht;
zend_object_value obj;
zend_ast *ast;
} zvalue_value;
Я немного соврал, когда сказал что PHP не управляет строками как собственной структурой. Фактически в PHP 5 троки используются в str поле zval (PHP контейнер переменной). Графически это можно представить так:
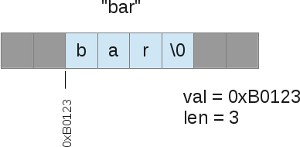
Проблемы в PHP 5
Модель обладает рядом проблем, некоторые имеются в ранних PHP 5 версиях, другие в новой PHP 7 реализации, о последних мы поговорим позже.
Размер Integer
Первое, это то что мы храним размер строки как integer, который зависит от платформы. На LP64(~Linux/Unix) integer весит 4 байта, но на ILP64 (SPARC64) он весит уже 8 байт. Тоже самое и для 32 битных вариантов. Так, в зависимости от вашей платформы, PHP будет вести себя по-разному, и иметь разное потребление памяти, что никто действительно никто не ожидает. Это показывает отсутствие согласованности в поддержке разных платформ (а концепция PHP всегда была направлена на это), и поиск ошибок затрудняется. Так же, но я думаю это довольно редкий случай, вы не сможете хранить в PHP стоке строку, которая больше размера integer. Т.е. в Linux LP64 вы не сможете иметь строк, длина которых больше 2^31, даже если ваш CPU 64 бит.
Нет единой структуры
Следующая проблема: до тех пор, пока мы не используем zval контейнер (и его str поле), мы, в конечном счёте, вынуждены дублировать концепцию. Везде, где мы поддерживаем бинарные строки везде в ядре, а это не редко в PHP 5, мы можем увидеть снова такую же структуру, но вынесенную из zval контейнера. Пример:
struct _zend_class_entry {
char type;
const char *name; /* C string buffer, NULL terminated */
zend_uint name_length; /* String length : num of ASCII chars */
...
Приведённый выше код показывает фрагмент PHP класса, структуру zend_class_entry. Как вы видите, тут тоже своё определение строки: char *name и zend_unit name_length, которое содержит длину.
А что на счёт хеш-таблиц?
typedef struct _zend_hash_key {
const char *arKey; /* C string buffer, NULL terminated */
uint nKeyLength; /* String length : num of ASCII chars */
ulong h;
} zend_hash_key;
Опять же, zend_hach_key структура часто используется, когда речь идёт об использовании хеш-таблиц (это очень распространённый случай). И мы снова видим, что концепция PHP строки ещё раз дублируется: const char* arKey и его unit nKeyLength.
Обратите внимание, что в каждом случае длина это typedef, что будет приведено к зависимому от платформы integer (zend_unit, uint, int). Некоторые могут быть даже со знаком, что уменьшает емкость в два раза.
Подводя итоги второй проблемы, не существует единого способа представления строк в PHP 5. Концепция их одинаковая: char* буфер вместе с его диной, но она определена не в одном месте PHP кода, из-за чего возникает дублирование кода и следующая проблема.
Использование памяти
Последняя проблема это потребление памяти. Если PHP встречает дважды одну и туже строку, он скорее всего хранит эту строку дважды в памяти, или даже больше. Добавляя к строке сверху каждую её часть, вы можете увидеть что это не так уж и мало: потребление памяти будет увеличиваться из-за различных копий одной и той же части строки в памяти.
К примеру, два внутренних слоя взаимодействуют друг с другом, верхний слой посылает строку для нижнего. Если нижний слой хочет сохранить эту строку для себя, в качестве примера (не предполагая её изменение), в PHP 5 он не имеет другого выхода, кроме как скопировать всю строку. Он не может держать указатель, потому что верхний слой может удалить указатель когда он захочет, и так же нижний слой может сделать это когда угодно, без риска ошибки для верхнего слоя при использовании указателя после освобождения.
Небольшой простой пример для иллюстрации:
static PHP_FUNCTION(session_id)
{
char *name = NULL;
int name_len, argc = ZEND_NUM_ARGS();
if (zend_parse_parameters(argc TSRMLS_CC, "|s", &name, &name_len) == FAILURE) {
return;
}
/* ... ... */
if (name) {
if (PS(id)) {
efree(PS(id));
}
PS(id) = estrndup(name, name_len);
}
}
Это session_id() это PHP функция. Она получает строку как входное значение (name), и должна сохранить его внутри в модуле сессии (в PS(id)), для хранения и использования значения после. Это делается с помощью полного дублирования входной строки (функцией estrndub(), это функция дублирует строку в памяти). Почему дублирования? Потому что если мы изменим id сессии снова, мы освободим последний id, но если эта последняя строка id была использована где-либо (в переменных PHP), тогда вы получите ошибку при чтении освобождённых данных. Обратная проблема: если мы просто храним указатель в модуле сессии без дублирования строки, что случится если вы, пользователь PHP, уничтожите значение, которое хранилось в $id? Мы оказываемся в похожей (но перевёрнутой) ситуации: модуль сессии попробует использовать освобождённый указатель и получит ошибку.
Такие ситуации, когда мы дублируем строки в памяти для дальнейшего использования, часто происходят в PHP коде. Если вы сохраните структуру памяти процесса PHP в середине его работы, вы сможете обнаружить много байт памяти, занятые дублирующими строки. Это пустое использование памяти машины.
Для решения этой проблемы, в PHP 5.4 добавили широко известную концепцию: пул строк. В PHP 7 была переработана глобальная концепция строки, теперь она последовательна и адекватна по потреблению памяти.
До PHP 5.4 не было согласованности в отношении управления строками в памяти. Это приводило к низкой производительностью, как относительно к процессору, так и в потреблении памяти, особенно когда веб приложение большое.
Решения, реализованные в PHP 5 для управления строками
PHP 5 пыталось решить проблему потребления памяти, и ему удалось найти разумное решение. Другие проблемы, которые были описаны ранее, были решены только в PHP 7, потому что это требовало много времени и значительного переписывания кода.
Пул строк
До PHP 5.4, все проблемы с управлением строк ещё присутствовали. Начиная с PHP 5.4, концепция пула строк была реализована, и в результате уменьшено потребление памяти, что решило одну из актуальных проблем (самую большую на мой взгляд).
Но, как вы видите, пул строк требует наличие глобального буфера, что по определению не потокобезопасно. Поэтому, на данный момент, пул строк не поддерживается ZTS PHP.
Пул строк полностью выключен, если вы запускаете PHP в ZTS моде. Вы будете страдать от расхода памяти в строках по сравнению с запуска без ZTS мода.
Что такое пул строк?
Если вы воспользуетесь поиском по фразе «пул строк», вы найдёте много страниц с описанием. Это означает, что мы встречаемся с общим понятием, реализованным в других языках программирования, таких как Python или Java, и даже в больших автономных приложениях, таких как ваша любимая IDE, или любимая игра (да, последние часто это просто большое C++ приложение).
Пул строк обеспечивает то, что та же самая строка (например «bar») никогда не будет сохранена в памяти более одного раза для одного процесса. Это достаточно просто, не так ли? Но как PHP реализует это концепцию, ещё в PHP 5.4? Давайте посмотрим вместе.
Пул строк гарантирует хранение строки в памяти не более одного раза для процесса. Для управления большими строками, или их большим количеством (как в PHP), это может сильно снизить потребление памяти, а так же сделать манипуляции со строками более производительными.
Концепция простая. Каждый раз, когда мы встречаем строку, вместо того чтобы создать её с помощью классического malloc() (мы предполагаем динамические строки, которым не может быть выделена память на стеке), мы сохраняем строку в буфер и добавляем её в словарь (который является хеш-таблицей). Если эта строка уже была в словаре, API возвращает указатель, что эффективно предотвращает создание ещё одной строки в памяти.
Вот как мы подготавливаем буфер, на начальном этапе запуска PHP:
void zend_interned_strings_init(TSRMLS_D)
{
size_t size = 1024 * 1024;
CG(interned_strings_start) = malloc(size);
CG(interned_strings_top) = CG(interned_strings_start);
CG(interned_strings_snapshot_top) = CG(interned_strings_start);
CG(interned_strings_end) = CG(interned_strings_start) + size;
zend_hash_init(&CG(interned_strings), 0, NULL, NULL, 1);
CG(interned_strings).nTableMask = CG(interned_strings).nTableSize - 1;
CG(interned_strings).arBuckets = (Bucket **) pecalloc(CG(interned_strings).nTableSize, sizeof(Bucket *), CG(interned_strings).persistent);
}
В первую очередь вы должны понять что буфер пула строк размером 1 мб (1024*1024) и не может быть изменён пользователем PHP (в настройках). Фактически, когда буфер полон, его размер не будет изменён и с этого момента API пула строк ведёт себя так, будто пула строк нет: для создания срок использованию malloc().
Теперь, чтобы создать строку в пуле, мы внутри используем zend_new_intered_string(), а не malloc() или strdup() и другие:
#define IS_INTERNED(s) \
(((s) >= CG(interned_strings_start)) && ((s) < CG(interned_strings_end))) static const char *zend_new_interned_string_int(const char *arKey, int nKeyLength, int free_src TSRMLS_DC) { ulong h; uint nIndex; Bucket *p; if (IS_INTERNED(arKey)) { return arKey; } h = zend_inline_hash_func(arKey, nKeyLength); nIndex = h & CG(interned_strings).nTableMask; p = CG(interned_strings).arBuckets[nIndex]; while (p != NULL) { if ((p->h == h) && (p->nKeyLength == nKeyLength)) {
if (!memcmp(p->arKey, arKey, nKeyLength)) {
if (free_src) {
efree((void *)arKey);
}
return p->arKey;
}
}
p = p->pNext;
}
/* ... ... */
Как вы можете видеть, API сразу же возвращает строку, которую вы хотите создать, если ранее она уже была в пуле строк. Если нет, то происходит поиск такой же строки по хештаблице пула строк. Просмотр хештаблицы и сравнение строк побайтово это тяжелые операции. Они обе сбросят ваш L1 CPU кеш, и, возможно, L2 кеш тоже. Но мы создаём строку в пуле только когда необходимо, и это улучшает производительность в будущем (при активном использовании строки). Это компромисс между работой по созданию строки (тяжелой) и работой по использовании этих строк в будущем (что просто). Если строка найдена в хештаблице, возвращается указатель на неё, а при указании последнего параметра как 1, оригинальная строка освобождается.
Давайте продолжим:
if (CG(interned_strings_top) + ZEND_MM_ALIGNED_SIZE(sizeof(Bucket) + nKeyLength) >=
CG(interned_strings_end)) {
/* no memory */
return arKey;
}
Как я и сказал, если буфер для хранения строк заполнен, API просто возвращает указатель на строку, которую мы послали. Далее:
p = (Bucket *) CG(interned_strings_top); /* reserve room from our allocated buffer */
CG(interned_strings_top) += ZEND_MM_ALIGNED_SIZE(sizeof(Bucket) + nKeyLength); /* move up the border */
h = zend_inline_hash_func(arKey, nKeyLength);
p->arKey = (char*)(p+1);
memcpy((char*)p->arKey, arKey, nKeyLength); /* copy the string into the interned string buffer */
if (free_src) {
efree((void *)arKey); /* free the original string */
}
p->nKeyLength = nKeyLength;
p->h = h;
p->pData = &p->pDataPtr;
p->pDataPtr = p;
/* ... ... */
return p->arKey; /* return the interned string */
И в конце строка дублируется (memcpy()) с указателя, который мы послали (arKey), в хештаблицу, для которой будет выделена память из буфера.
Как вы можете видеть, нет ничего действительно сложного, просто несколько умных уловок для увеличения производительности будущих манипуляций со связанными строками. Например, хеш строки (переменная h), вычисляется каждый раз, когда мы добавляем строку. Этот хеш будет нужен при любом использовании строки как ключа хештаблицы, а это скорее всего произойдёт, поэтому лучше его высчитать сейчас, чем позже при выполнении, когда производительность будет более важна.
Интернирование строк выполняется один раз, когда PHP запускается или когда компилирует скрипт, но никогда на стадии выполнения.
Теперь мы должны подумать об удалении строк. Как вы уже поняли, пул строк возвращает указатели, и строки никогда не должны быть случайно удалены кем-либо, потому что они могут использоваться где-то ещё, где может получиться ошибка использования памяти.
Таким образом, если мы хотим удалить данную строку, мы должны узнать используется ли она где-либо ещё. Для этого, мы должны использовать вместо efree() (free() это эквивалент в PHP коде), функцию str_efree(), которая учитывает интернированные строки.
#define str_efree(s) do { \
if (!IS_INTERNED(s)) { \
efree((char*)s); \
} \
} while (0)
Мы можем увидеть что интернированные строки не уничтожаются, когда мы об этом просим, если они используются ещё где-либо.
Так же, если вы хотите сделать копию указателя на строку только для чтения, используйте str_estrdup(), вместо estrdup(). Смотрите:
#define str_estrndup(str, len) \
(IS_INTERNED(str) ? (str) : estrndup((str), (len)))
Очевидно, интернированные строки это общие строки только для чтения. И каждый раз, когда вы хотите их изменить для собственного использования, вы дублируете их в памяти и работаете с копией. Но часто строка используется только на чтение, так что нет необходимости дублировать её в памяти, если строка в пуле.
Интернированные строки это общие строки + только для чтения, не пытайтесь использовать free() для них, и не изменяйте их непосредственно. Основа API это вызов zend_new_interned_string_int(), возвращающий const char*. Если вам нужно записать в интернированную строку, создайте копию сначала, и работайте с этой копией (воспользуйтесь efree() когда закончите).
Видите как умно интернированные строки располагаются в памяти? Вот как может выглядеть распределение памяти:

Интернированные строки хранятся в известном участке памяти, поэтому чтобы проверить что указатель содержит интернированную строку, мы просто проверяем что его адрес попадает в диапазон буфера строк:
#define IS_INTERNED(s) \
(((s) >= CG(interned_strings_start)) && ((s) < CG(interned_strings_end)))
Это высокопроизводительно, если мы посмотрим на Хеш-таблицы: каждый раз мы хотим знать интернированная строка или нет.
Итак, как на самом деле удалить интернированную строку? Вы не делаете это в PHP расширении. Движок освободит весь пул строк сразу, по окончанию выполнения скрипта.
void zend_interned_strings_dtor(TSRMLS_D)
{
free(CG(interned_strings).arBuckets);
free(CG(interned_strings_start));
}
Это эффективнее, потому что буфер это непрерывный участок памяти, и операция освобождения удаляет все строки за раз, вместо удаления одной строки за одну операцию (как в PHP < 5.4).
В начале запроса мы изменяем границу буфера:
static void zend_interned_strings_snapshot_int(TSRMLS_D)
{
CG(interned_strings_snapshot_top) = CG(interned_strings_top);
}
И в конце запроса мы восстанавливаем его, а так же удаляем все ссылки на строки из хештаблицы:
static void zend_interned_strings_restore_int(TSRMLS_D)
{
Bucket *p;
int i;
CG(interned_strings_top) = CG(interned_strings_snapshot_top);
for (i = 0; i < CG(interned_strings).nTableSize; i++) { p = CG(interned_strings).arBuckets[i]; while (p && p->arKey > CG(interned_strings_top)) {
CG(interned_strings).nNumOfElements--;
if (p->pListLast != NULL) {
p->pListLast->pListNext = p->pListNext;
} else {
CG(interned_strings).pListHead = p->pListNext;
}
/* ... */
}
}
Теперь, чтобы увидеть конкретный пример использования интернированных строк, давайте посмотрим вместе на компилятор PHP:
void zend_do_begin_class_declaration(const znode *class_token, znode *class_name, const znode *parent_class_name TSRMLS_DC)
{
/* ... ... */
new_class_entry = emalloc(sizeof(zend_class_entry));
new_class_entry->type = ZEND_USER_CLASS;
new_class_entry->name = zend_new_interned_string(Z_STRVAL(class_name->u.constant), Z_STRLEN(class_name->u.constant) + 1, 1 TSRMLS_CC);
new_class_entry->name_length = Z_STRLEN(class_name->u.constant);
/* ... ... */
Код выше срабатывает, когда PHP компилирует пользовательский класс, например class Bar { }. Как вы можете видеть, имя класса будет занесено в пул строк, с помощью zend_new_interned_string(). Он посылает указатель на строку с именем класса, которая приходит с парсера (class_name->u.constant), и функция возвращает другую строку, но уже из пула строк. Так же, старая строка будет удалена, а указатель на неё перестанет быть валидным (1 посылается последним параметром в zend_new_interned_string(), что означает «удали оригинальную строку, чтобы я не делал это самостоятельно»).
Если мы продолжим анализировать компилятор, мы увидим что он делает тоже самое во многих случаях: именах строк, переменных, констант, пользовательских PHP строках и в более сложных случаях.
Вот как может быть выглядеть структура памяти строк какого-нибудь PHP скрипта:
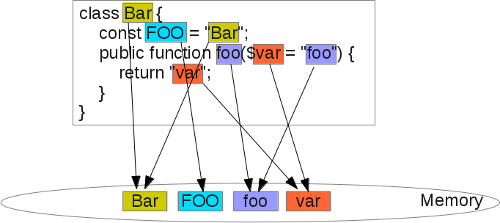
Каждая строка хранится только единожды, и они все хранятся в одном непрерывном буфере, а не распределены по всей памяти, что улучшает эффективность кеша процессора.
Суммарно об интернированных строках
Интернированные строки это программный механизм, предназначенный для хранения любой строки (char *) в памяти только в одном экземпляре. Это глобальная концепция, рассчитанная только на чтение: не следует изменять интернированные строки (для этого обычно возвращается const char* указатель), ни удалять их. Кроме того, понятие включает в себя глобальный буфер, что требует осторожности при работе в многопоточном режиме. В PHP ZTS пул строк просто выключен.
Интернированные строки имеют множество преимуществ:
- Они уменьшают потребление памяти, и эта экономия может быть огромна для больших приложений с кучей функций, классов, переменных.
- Хеш интернированной строки вычисляется только один раз и далее используется если необходимо (а это бывает часто). Это уменьшает нагрузку на CPU во время выполнения PHP.
- Сравнение двух строк является сравнением двух указателей, без сканирования памяти, что очень производительно.
И также недостатки:
- Создание интернированной строки часто требует сканирования хештаблицы, а иногда и два буфера строк (
memcmp()); эти затраты должны дать выгоду позже. - Разработчики расширений должны всегда помнить что любая строка может быть интернированной, и никогда не должны пытаться вызвать free() (приведёт к ошибке) или модифицировать строку.
- Так как компилятор использует интернированный строки, он медленнее, но скорее всего это даст ускорение на этапе выполнения. Вы можете использовать кеширование байт-кода для получения большего преимущества от использования пула строк.
OPCache расширение для PHP продвигает концепцию интернированных строк ещё дальше, с помощью общего буфера строк для нескольких процессов PHP, и позволяя пользователям настраивать пространство для буфера (с помощью INI параметров), когда как традиционный PHP не разрешает такого.
Путь PHP 7
В PHP 7 изменено много вещей в том, как PHP манипулирует строками.
Наконец настоящая общая структура и его API
В PHP 7 наконец централизованная концепция строк, которая используется везде в PHP, где используются строки:
struct _zend_string {
zend_refcounted_h gc;
zend_ulong h;
size_t len;
char val[1];
};
3 вещи заметны в приведённой выше структуре:
- Размер строки хранится с использованиям size_t type.
- Строка декларируется не как char *, а как char[1].
- Подсчёт ссылок:
Так как длина определена как size_t переменная, её вес зависит от размерности платформы. Одна из проблем PHP 5 была решена: для CPU64 длина строки всегда 8 байт для любой платформы (это определение Cи типа size_t).
Строки хранятся в char[1], вместо char*, этот трюк в C называется «struct hack» (посмотрите термин если необходимо). Это позволяет выделить буфер строки вместе с zend_string буфером.
Обратите внимание, что теперь строки по-умолчанию включают хеш (h). Таким образом мы вычисляем хеш для заданной строки только один раз (обычно во время компилирования), и никогда после. В PHP, главным образом до введение интернированных строк (<5.4), хеш строки пересчитывался каждый раз, когда он был нужен, что попусту тратило время процессора. Предварительное вычисление хеша улучшает производительность PHP.
В строках подсчитываются ссылки! В PHP 7 для строк подсчитываются ссылки (так же как и для многих других примитивных типов). Это означает, что интернированные строки по-прежнему актуальны, но меньше: PHP слои теперь могут отправлять строки друг другу и, поскольку для строк считаются ссылки, мы можем быть уверены что строка не будет удалена пока она используется где-либо ещё.
Концепция подсчёта строк: мы считаем каждое место, где строка используется, поэтому строка будет удалена только когда никто её больше не использует где-либо ещё.
Давайте вернёмся в пример модуля сессий. Вот код PHP 5 и PHP 7 только той части, где идёт управление строками:
/* PHP 5 */
static PHP_FUNCTION(session_id)
{
char *name = NULL;
int name_len, argc = ZEND_NUM_ARGS();
/* ... */
if (name) {
if (PS(id)) {
efree(PS(id));
}
PS(id) = estrndup(name, name_len);
}
}
/* PHP 7 */
static PHP_FUNCTION(session_id)
{
zend_string *name = NULL;
int argc = ZEND_NUM_ARGS();
/* ... */
if (name) {
if (PS(id)) {
zend_string_release(PS(id));
}
PS(id) = zend_string_copy(name);
}
}
Как вы можете видеть, мы используем zend_string структуру в PHP 7, и мы используем функции API zend_string_release() и zend_string_copy().
static zend_always_inline zend_string *zend_string_copy(zend_string *s)
{
if (!ZSTR_IS_INTERNED(s)) {
GC_REFCOUNT(s)++;
}
return s;
}
static zend_always_inline void zend_string_release(zend_string *s)
{
if (!ZSTR_IS_INTERNED(s)) {
if (--GC_REFCOUNT(s) == 0) {
pefree(s, GC_FLAGS(s) & IS_STR_PERSISTENT);
}
}
}
Это просто подсчёт ссылок: строка посылается в модуль PHP сессии и этот модуль сохраняет указатель на строку, не копируя её в памяти, как делал PHP 5.
Это большой шаг вперёд в управлении строками в PHP.
В PHP 7 добавлена настоящая структура и API для управления строками. Это большой шаг вперёд в согласованности, потреблении памяти и производительности.
Если вы хотите использовать zend_string API, он встроен (из соображений производительности) и хранится в zend_string.h.
Интернированные строки всё ещё имеют значение
Как мы видим, строки в PHP 7 подсчитывают ссылки, что позволяет нам не копировать их в памяти когда мы хотим передать строку из одного слоя в другой.
Но, интернированные строки всё ещё нужны. Они по-прежнему используются в PHP 7, и работают почти так же, как в PHP 5, кроме того что мы не используем более специального буфера, потому что можем показать сборщику мусора, что zend_string интернирован (структура теперь позволяет сделать это).
Так, создание интернированной строки в PHP 7, является созданием zend_string и флаг IS_STR_INTERNED. Когда удаляется zend_string, используется zend_string_release(), API проверяет что строка интернирована, и если да, то просто ничего не делает. Интернированные строки разрушаются почти так же, как в PHP 5, но этот процесс в PHP 7 оптимизирован благодаря новому распределению памяти и механизму сборки мусора.
Тяжелая миграция
Представляете? Замена каждого места в исходном коде PHP (~750 тысяч строк), где используется char*/int, на zend_string и его API это не лёгкая работа. Вы можете увидеть один коммит с подобной огромной работой.
Это не могло произойти в PHP 5, потому что zend_string ломает ABI, и мы не можем этого сделать не меняя основную версию PHP.
Миграция PHP расширений это непростая задача, а zend_string это не единственное изменение в PHP 7, много и других структур значительно изменились. Поскольку ABI был сломан между PHP 5 и 7, очевидно что не все ваши любимые PHP 5 расширения будут работать в PHP 7.
Выводы
Теперь вы видите как PHP управляет строками. Большая часть строк приходит из PHP компилятора от пользовательских скриптов. PHP 5, начиная с 5.4, вводит интернированные строки, что означает сохранение памяти с помощью отсутствия дублирования строк в памяти. До PHP 5.4 управления строками явно не хватает.
Начиная с PHP 7, добавлена новая структура и прекрасное API для управления строками, основанное на подсчёте ссылок. В результате ещё большая экономия памяти и общая согласованность в языке.
Оригинальный текст вы можете прочитать тут
— Безопасное для обработки данных в двоичной форме сравнение 2 строк со смещением, с учетом или без учета регистра
о чём вы?